Tensor completion (example of minimizing a loss w.r.t. TT-tensor)¶
Open this page in an interactive mode via Google Colaboratory.
In this example we will see how can we do tensor completion with t3f, i.e. observe a fraction of values in a tensor and recover the rest by assuming that the original tensor has low TT-rank. Mathematically it means that we have a binary mask \(P\) and a ground truth tensor \(A\), but we observe only a noisy and sparsified version of \(A\): \(P \odot (\hat{A})\), where \(\odot\) is the elementwise product (applying the binary mask) and \(\hat{A} = A + \text{noise}\). In this case our task reduces to the following optimization problem:
[1]:
import numpy as np
import tensorflow as tf
tf.set_random_seed(0)
np.random.seed(0)
%matplotlib inline
import matplotlib.pyplot as plt
try:
import t3f
except ImportError:
# Install T3F if it's not already installed.
!git clone https://github.com/Bihaqo/t3f.git
!cd t3f; pip install .
import t3f
Generating problem instance
Lets generate a random matrix \(A\), noise, and mask \(P\).
[2]:
shape = (3, 4, 4, 5, 7, 5)
# Fix random seed so the results are comparable between runs.
tf.set_random_seed(0)
# Generate ground truth tensor A. To make sure that it has low TT-rank,
# let's generate a random tt-rank 5 tensor and apply t3f.full to it to convert to actual tensor.
ground_truth = t3f.full(t3f.random_tensor(shape, tt_rank=5))
# Make a (non trainable) variable out of ground truth. Otherwise, it will be randomly regenerated on each sess.run.
ground_truth = tf.get_variable('ground_truth', initializer=ground_truth, trainable=False)
noise = 1e-2 * tf.get_variable('noise', initializer=tf.random_normal(shape), trainable=False)
noisy_ground_truth = ground_truth + noise
# Observe 25% of the tensor values.
sparsity_mask = tf.cast(tf.random_uniform(shape) <= 0.25, tf.float32)
sparsity_mask = tf.get_variable('sparsity_mask', initializer=sparsity_mask, trainable=False)
sparse_observation = noisy_ground_truth * sparsity_mask
Initialize the variable and compute the loss
[3]:
observed_total = tf.reduce_sum(sparsity_mask)
total = np.prod(shape)
initialization = t3f.random_tensor(shape, tt_rank=5)
estimated = t3f.get_variable('estimated', initializer=initialization)
# Loss is MSE between the estimated and ground-truth tensor as computed in the observed cells.
loss = 1.0 / observed_total * tf.reduce_sum((sparsity_mask * t3f.full(estimated) - sparse_observation)**2)
# Test loss is MSE between the estimated tensor and full (and not noisy) ground-truth tensor A.
test_loss = 1.0 / total * tf.reduce_sum((t3f.full(estimated) - ground_truth)**2)
SGD optimization¶
The simplest way to solve the optimization problem is Stochastic Gradient Descent: let TensorFlow differentiate the loss w.r.t. the factors (cores) of the TensorTrain decomposition of the estimated tensor and minimize the loss with your favourite SGD variation.
[4]:
optimizer = tf.train.AdamOptimizer(learning_rate=0.01)
step = optimizer.minimize(loss)
[5]:
sess = tf.Session()
sess.run(tf.global_variables_initializer())
train_loss_hist = []
test_loss_hist = []
for i in range(10000):
_, tr_loss_v, test_loss_v = sess.run([step, loss, test_loss])
train_loss_hist.append(tr_loss_v)
test_loss_hist.append(test_loss_v)
if i % 1000 == 0:
print(i, tr_loss_v, test_loss_v)
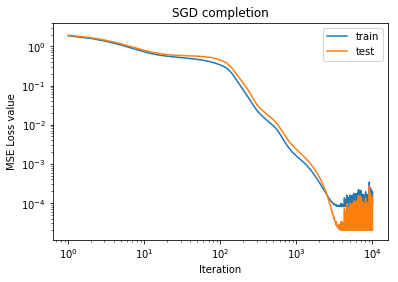
0 2.20282 2.26653
1000 0.00158865 0.00234495
2000 0.000334849 0.00045755
3000 9.98362e-05 5.27664e-05
4000 8.28005e-05 2.14205e-05
5000 8.17184e-05 2.07301e-05
6000 8.57184e-05 2.59403e-05
7000 8.1738e-05 2.07167e-05
8000 0.000102493 4.31596e-05
9000 8.5987e-05 2.29819e-05
[6]:
plt.loglog(train_loss_hist, label='train')
plt.loglog(test_loss_hist, label='test')
plt.xlabel('Iteration')
plt.ylabel('MSE Loss value')
plt.title('SGD completion')
plt.legend()
[6]:
<matplotlib.legend.Legend at 0x1821244048>
Speeding it up¶
The simple solution we have so far assumes that loss is computed by materializing the full estimated tensor and then zeroing out unobserved elements. If the tensors are really large and the fraction of observerd values is small (e.g. less than 1%), it may be much more efficient to directly work only with the observed elements.
[7]:
tf.reset_default_graph()
shape = (10, 10, 10, 10, 10, 10, 10)
total_observed = np.prod(shape)
# Since now the tensor is too large to work with explicitly,
# we don't want to generate binary mask,
# but we would rather generate indecies of observed cells.
ratio = 0.001
# Let us simply randomly pick some indecies (it may happen
# that we will get duplicates but probability of that
# is 10^(-14) so lets not bother for now)
num_observed = int(ratio * total_observed)
observation_idx = np.random.randint(0, 10, size=(num_observed, len(shape)))
# and let us generate some values of the tensor to be approximated
observations = np.random.randn(num_observed)
[8]:
# Our strategy is to feed the observation_idx
# into the tensor in the Tensor Train format and compute MSE between
# the obtained values and the desired values
[9]:
initialization = t3f.random_tensor(shape, tt_rank=16)
estimated = t3f.get_variable('estimated', initializer=initialization)
[10]:
# To collect the values of a TT tensor (withour forming the full tensor)
# we use the function t3f.gather_nd
[11]:
estimated_vals = t3f.gather_nd(estimated, observation_idx)
loss = tf.reduce_mean((estimated_vals - observations) ** 2)
[12]:
optimizer = tf.train.AdamOptimizer(learning_rate=0.01)
step = optimizer.minimize(loss)
[13]:
sess = tf.Session()
sess.run(tf.global_variables_initializer())
loss_hist = []
for i in range(2000):
_, loss_v = sess.run([step, loss])
loss_hist.append(loss_v)
if i % 100 == 0:
print(i, loss_v)
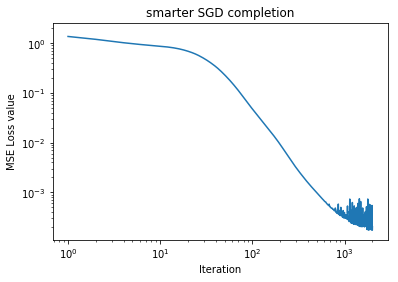
0 1.64438
100 0.0472497
200 0.00913698
300 0.00306178
400 0.00155388
500 0.000971667
600 0.000669613
700 0.000499607
800 0.000437507
900 0.000346848
1000 0.000325652
1100 0.000275839
1200 0.000247506
1300 0.000410816
1400 0.000331641
1500 0.000296677
1600 0.00025365
1700 0.000210029
1800 0.000216491
1900 0.000312779
[14]:
plt.loglog(loss_hist)
plt.xlabel('Iteration')
plt.ylabel('MSE Loss value')
plt.title('smarter SGD completion')
plt.legend()
[15]:
print(sess.run(t3f.gather_nd(estimated, observation_idx)))
[-0.10904536 -1.38673067 -0.53866088 ..., -0.0059163 0.22185898
0.74981755]
[16]:
print(observations)
[ -1.27225139e-01 -1.37794858e+00 -5.42469328e-01 ..., -1.30643336e-03
2.35629296e-01 7.53320726e-01]
[ ]: